A Real-time AI Companion That Doesn't Always Respond, Can Watch And Talk To Me, And Change States
Is it me or are all AI companions/girlfriends/boyfriends the same? I’m not a super user by any means (hedging in case a future girlfriend is reading this), but I had a lot of customers in the space back when I was building consumer AI voice infra.
Differentiation among these apps typically comes down to some ratio of features.
- How configurable is your companion?
- How much is about generating images?
- Is there a community?
- Are the characters recognizable characters?
- Does the AI remember past conversations?
These are real differences, but they are differences of degree, not kind. The experience across each application is basically the same. It’s an LLM wrapper with some image generation model, maybe a memory system (or it’s just using a long context LLM with some summarization system). A surprising few use voice integrations, and speaking from a guy who looked at the invoices sent to customers, those voice features were a single digit percentage of the total usage.
It’s like a long distance girlfriend/boyfriend in 2016. You can text, you’re maybe talking on the phone, and you might get a photo occasionally. But long term relationships are famously awful. It’s essentially a perpetual talking phase with someone you’d like to do more than talk to.
If that’s the case, won’t they get old? I mean maybe the user-bases of these apps would take a long-distance relationship over no relationship, but that isn’t exactly inspiring that our AI girlfriends/boyfriends are emulating the worst possible kind of relationship.
No one wants to just text and maybe get an image every once in a while. I want to see my beautiful girlfriend, AI or otherwise (still hedging).
AI Should Be Able To See Me, Watch Movies With Me, Game With Me
The header says it all. Everyone knows the hallmark of a good relationship is whether or not you’re watching TV shows together at night. So how do I recreate that experience?
And maybe we move beyond the Netflix and get to the chill. Shouldn’t the AI be able to see me? Shouldn’t it be able to respond to things I’m doing in the real world, ideally without me always having to say something first?
Even when we’re just chatting, I’d like it to be able to tell me I look handsome and tell me that 15 years of working out hasn’t just been to peacock to other men. Let me suspend disbelief. Let me have this.
And realism. We have the power of technology and we’re creating realistic girlfriends? Why exactly?
Shouldn’t we transcend real girlfriends (I am no longer hedging).
If I’m going to have an AI girlfriend, shouldn’t I be able to get it to do things a human girlfriend never would? You know what I’m talking about 😉.
I want my girlfriend to watch me play video games and not complain she’s bored or that the shooting is giving her a headache.
I’m trauma dumping.
How To Build An AI Companion To Watch Movies and Videogames With Me, And Watch Me
Ok, so video into AI. What do?
We’re in a bit of a technological renaissance right now. AI products are changing.
AI is no longer limited to text. It’s going multi-modal.
You might be saying AI has been multi-modal for a while with voice, but historically even conversational AI voice agents are just LLMs wrapped in a STT and TTS model (called the pipeline approach). Even speech-to-speech models are LLMs smashed together with a STT and TTS model, effectively resembling the pipelines, just with fewer network hops. These are fundamentally text-based applications.
That has changed. VLMs and Omni models are the hot thing right now. Models that can hear things directly without a STT model doing the translation. Models that can see the world in real-time. Models that have multiple senses to do multiple things.
You can now video chat with your model and it will understand your words, what you look like, and what you’re doing. You can ask it what you’re wearing, show it ingredients, have it count your fingers, and it can respond in mostly real-time.
These models—like Google Gemini 2.5 Live Video, Qwen3 VL—are magic.
Gemini is especially interesting. I can stream video of me playing basketball from my phone’s camera to Google API and it will be able to tell me if my form needs work and somewhat reliably count the baskets I make (LLMs are bad at counting). I can even swap out tool calls on the fly. It's expensive ($3-4/hr), but if you need to do a simple task on a single stream of media, it's a great tool.
Qwen is also cool. I played some guitar chords for it and it was able to identify them correctly through sound alone. There isn't as much infrastructure around Qwen, so most of the testing I've done has been locally.
This opens the door for a new class of application. And guess what: AI companions fall under this umbrella. Build companions that are truly multi-modal.
The Difficulties of Building Multi-Modal Real-time AI Companions And Applications
You may be thinking great. Problem solved. Thanks Jack.
NOT SO FAST.
Simple applications like I described above are totally possible using Qwen or Gemini, but what if you’re not building something simple?
- What if you need the AI to do 3-4 things at once?
- What if you need to add multi-participant?
- What if your application has states?
- What if you need determinism and logic?
- What if you need the AI to not respond unless it’s pertinent?
If you answered yes to any of these your problem is not solved. You need more than just a multi-modal model. You need orchestration, you probably need at least 2 models running in parallel, you need some sort of state machine. The capabilities of the models has unblocked use cases, but building those use cases will remain out of reach for teams who can’t or don’t want to orchestrate all of that.
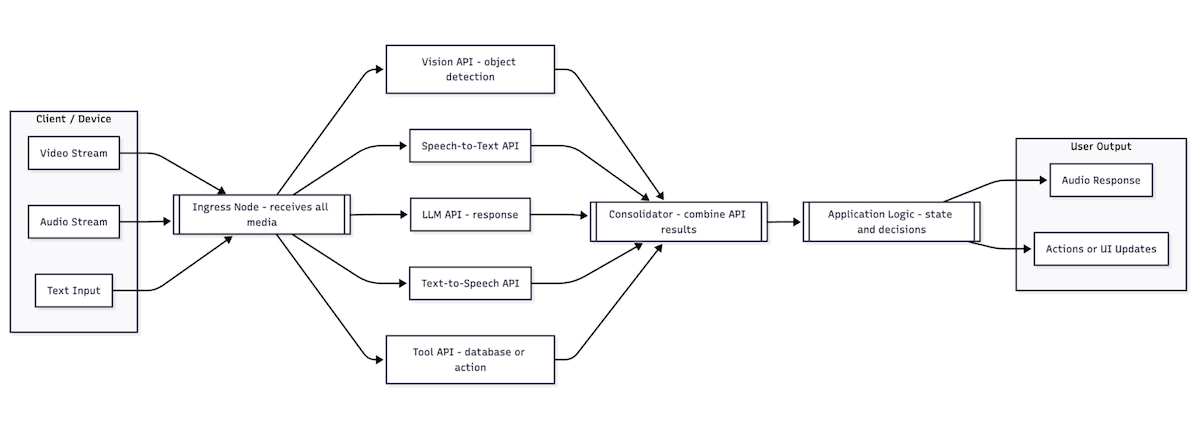
You need a system that can handle all of this stuff natively.
Why You Need Special Orchestration To Build Multi-modal AI Apps That Can See, Hear, And Speak
There are a few major problems that you will encounter when building something multi-modal.
The first is ingress: how do you get all the media streams in? This is a surprisingly difficult problem for real-time apps.
Once you have the data into your system, you’ve gotta send it off to your different model APIs. Each model has a margin, a latency, and a capacity, so now you’ve got to handle scheduling, capacity planning, and cost.
And then you’ve got to actually build the application logic. If you’re using states and logic so your companion is dynamic, you’re looking at days, if not weeks, of real engineering work.
Ron, you don’t have to do this!
How I Built A Multi-modal AI Girlfriend/Boyfriend/Companion That Can Watch Me, My Screen (Movies/Video Games), And Video Chat With Me
I just talked about why this is hard to do, and now I’m talking about how I built it. Am I amazing or what?
“or what” is the correct answer. I had the right tool for the job.
I used Gabber.
Gabber was purpose built to make these experiences possible. We had customers asking how they could do things that were easy to describe but hard to build, that needed determinism, that had a few models working together. Our answer was generally some variation of “that’s going to be really hard” or “that’s not possible”.
We even tried to build a simple AI-powered onboarding experience for our own app once and it took 3 days link to blog post on onboarding. 3 days for something that I could train a third grader to do.
Using Gabber I can have 2 states, I can manage a single or multiple LLM contexts simultaneously, I can create my application logic at the speed I can think it rather than code it, and I can bring my media into the system one time and have it go everywhere I need it to.
And actually building the thing was easy.
The AI I built lets me talk to it, screen share to it (movies/video games), and it will become obsessed if I show it a banana (yes, actual banana).
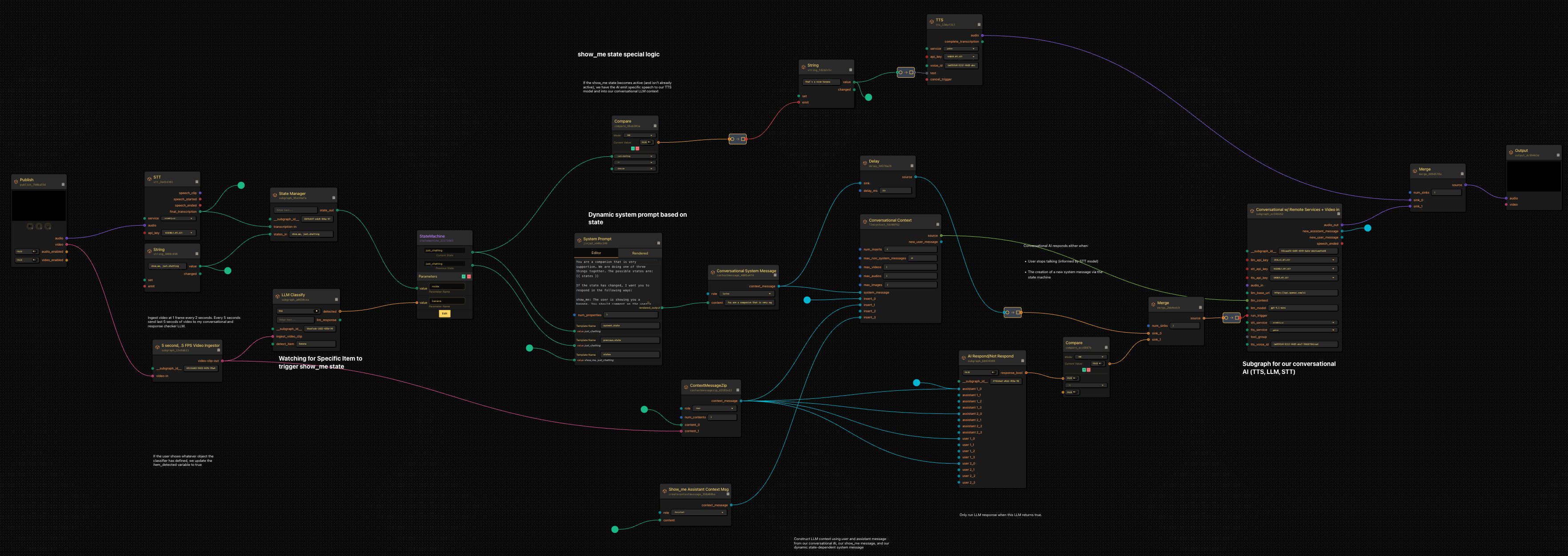
Now this looks like a lot, but it’s very simple. 4 parts working together.
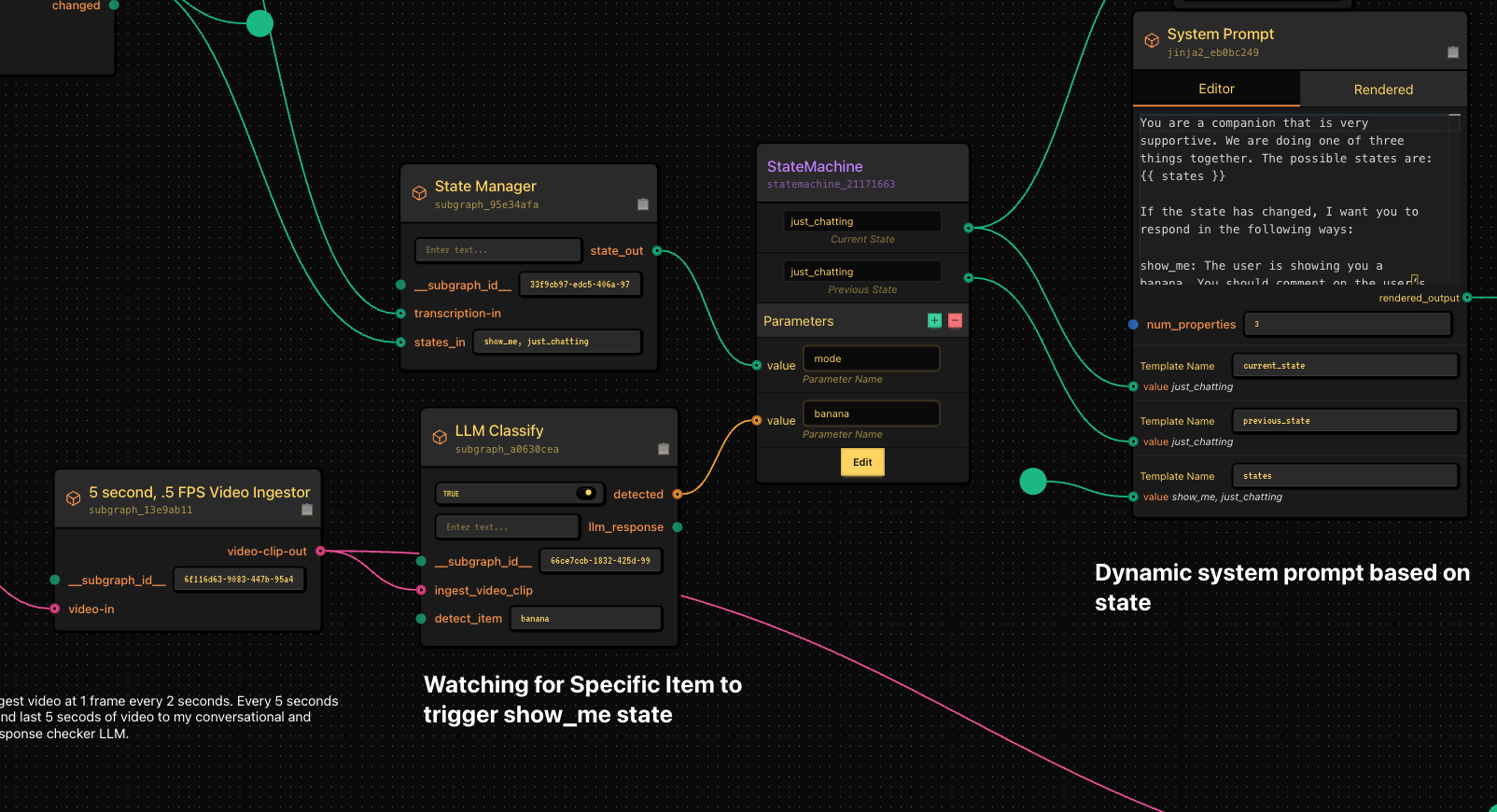
We have a state management system that’s dead simple.
- LLM listens to me. If I say “show_me” or “just_chatting”, it changes state If I simply show it a banana, it auto-transitions to the show_me state where it becomes curious about the banana. This is all controlled using jinja templating in our system prompt.
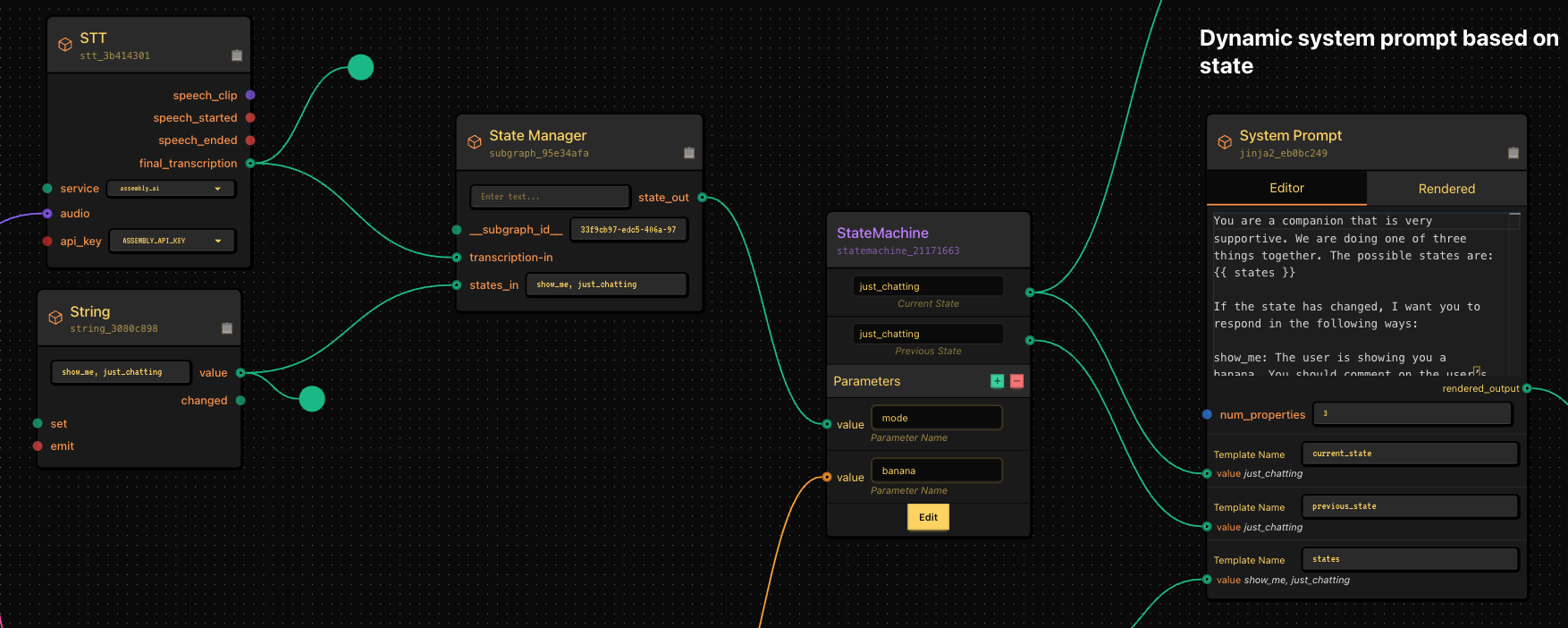
- I have some special logic that if the state changes to show_me, it injects “that’s a nice banana” into my TTS system as well my conversational LLM’s context.
- I have a conversational AI that ingests my speech + video, and receives output from my conversational AI.
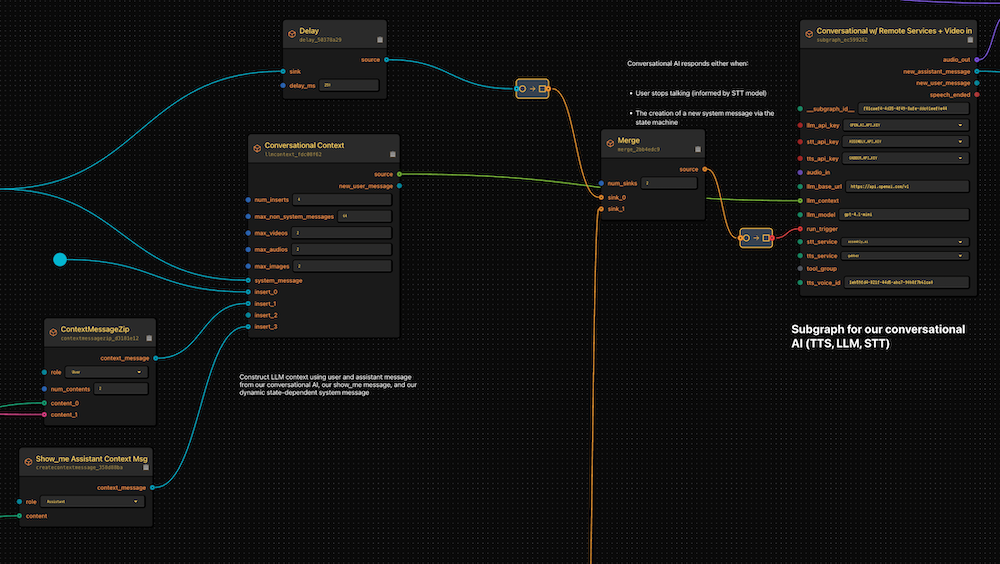
- I have a special workflow running along the bottom that acts as the “run trigger” to my conversational AI. This is optional, but useful if you don’t always want your AI to respond when you do something. Tl;dr instead of my run trigger being something like “when I stop speaking”, it can be “when a separate AI model decides it makes sense to respond”.
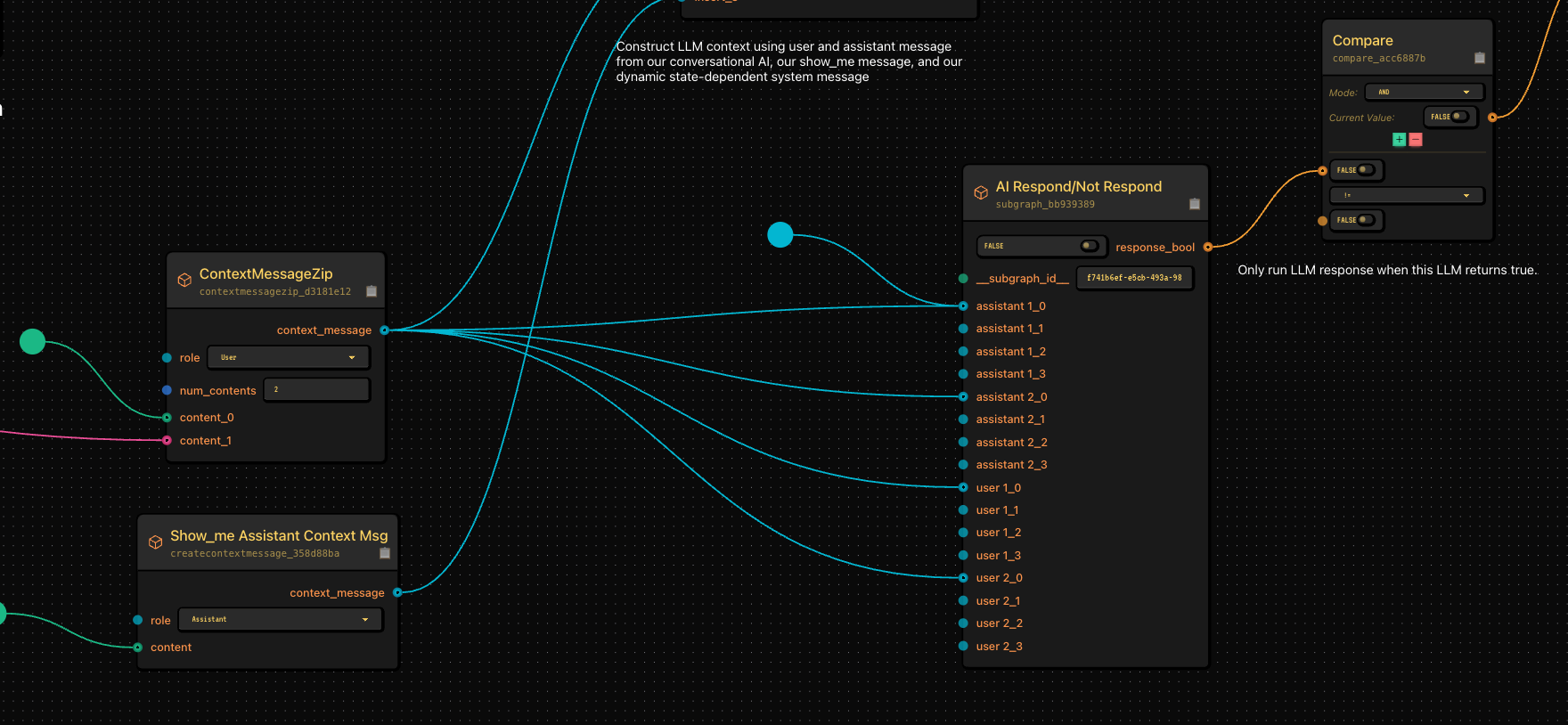
And that’s it’s. Here are close ups of the various steps I discussed. This is fully functional to run locally on your computer, and as soon as Gabber rolls out its hosted solution, you can click to deploy this in seconds.
Run A Local Or Cloud Based AI Companion That Can See You, Hear You, Talk To You, And Change State
This was a fun project because it let me combine 3 things I care deeply about: bananas, AI, and companionship.
If you want a copy of this project, hop into the Discord and ask or shoot me a DM on any platform.
Gabber will keep getting better, and I’ll keep building fun sample apps to help people get started. Follow along if that’s interesting, and don’t hesitate to reach out at any point.
Cheers.
Links
- GitHub: gabber-dev/gabber
- Twitter: @jackndwyer
- Discord: Join here