How We're Building A Real-time Multi-modal AI Backend With Deployable Graphs
AI apps used to be about text and code. Ask AI to write SQL for you. Have it design a function to sort values. Generate a blog post or email.
Then there were agents. They could chain tasks together, working out things sequentially and building on past outputs.
Then there was early multi-modal: voice. Speak into a microphone, a speech-to-text model translates that into text, the text goes into an LLM, and the LLM output gets spoken back the user via a text-to-speech model.

That’s a comprehensive history of Language-model-based AI thus far. I’m only sort of kidding. All the news you’ve heard about AI, and every unicorn you’ve heard of has powered or productized one of those things.
But there’s a common thread that has yet to be challenged.
They are all turn-based and sequential.
I’m not mad at that, I mean it's clearly valuable. But the world isn’t turn based. And depending on the definition (we’re going to conveniently use mine), it is not sequential.
Things happens all the time, at the same time. Those things affect each other. Sometimes more than one person is in a conversation.
For AI apps to truly hit the mainstream, especially realtime AI apps, they must operate the way the world does.
Going Multi-Modal
For AI to interact the world, two things need to change.
- It needs to be truly multi-modal: voice, video, screens, non-verbal audio, multiple-participants. It can’t all just be text in → text out.
- We need new developer system that handle multiple modalities the way our brain does: together and at the same time.

Voice, Video, Screens, and Microphones
Language models are getting really capable. Qwen3 VL, Gemini, GPT-5. They’re able to not just take text or images, but now audio and video. Same brain, now capable of 2 new modalities. That’s really big news.
You no longer need a custom computer vision model to detect specific objects, and you no longer need special models for really anything. LLMs are general intelligence, and now that general intelligence can be applied to vision and audio.
If the LLM is trained on enough visual and audio data, then you can do pretty much anything with it so long as you can figure out how to orchestrate it.
Moreover, new AI models have bigger context windows and increased intelligence, meaning they're better in every other way too.
Now teams can feed footage, screens, and audio from one or multiple sources into a modern LLM, and get an output for their application that is actually useful.
That’s magic.
But there’s a problem.
Building Anything Useful Requires Orchestration
These models are amazing. Some of them are even open-weights like Qwen3 VL. But they are still turn based.
Google Gemini’s Live API is turn based. You ask it what you’re wearing, a second later it says something a stylist would scoff at, at least in my case.
There’s still the constraint of feed something in -> wait for an output. It still expects prompting before something happens.
What’s more, it’s still just one thread.
I want to introduce a use case we’re excited about: an AI personal trainer.
This trainer needs to count my reps as they happen, which is already impossible without me saying something like “rep” every time I complete a rep. And what if I want it to interject when I round my back on a squat? And what if I want it to log my workout to a Google Doc? And what if I need it to automatically transition me to the next set using a timer and a state machine? And what if I want to talk to it sometimes? And what if I want it to do all of this automatically?
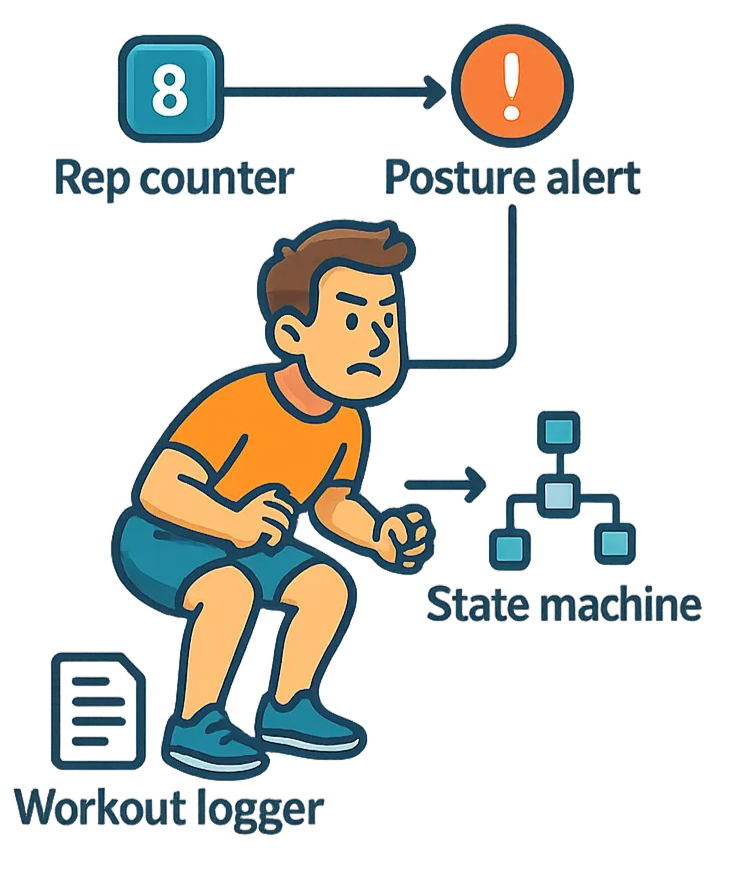
This should be a very simple application, but you can already see the problem. It's simple to describe, but it's not simple to build.
You cannot jam that into a prompt, and as someone who has tried to build a subset of those features using code, you don’t want to do that either; it will take you days and is basically impossible to iterate on.
That’s where we got graph-pilled.
Graph-Based Systems and Developer Approaches
We’ve come to believe that the deployable unit for these kinds of apps should be a graph. That’s true whether or not the frontend is visual. The backend needs to be.
There are two basic assumptions that lead to this:
- A single AI experience usually involves multiple inference steps — not just one model doing one thing.
- Those steps need to be colocated. You can’t pipe video all over the place — videos are big, and sending them around is lossy and expensive.

If you accept those two premises, then you’re left with three paths:
- Option A: Hope that one model can do everything with a really thorough prompt. (We don’t think this is realistic).
- Option B: Developers build their whole backend themselves from scratch. Think: deploying to GPUs, managing infra, building from the ground up. This is a bigger lift than 98% of teams we’ve talked to care to ever explore. Even the most well-funded companies don’t want to run GPUs.
- Option C: Developers define a graph of inference steps and integrate it at the application layer without touching infra. They’d use third party inference, orchestration, and networking.
We’ve landed on a hybrid between B and C. We host the models, handle the networking, and host the orchestration system. If developers want, they can integrate their own infra into our system or even self-host Gabber for internal use cases. They can also write code for the nodes, and we run them on firecracker VMs colocated with the models. That means you can do custom logic, while still taking advantage of managed inference and multi-modal streaming.
A New Developer System And Frontend GUIs
We know GUI builders breed skepticism.
Drag-and-drop tools often trade power for simplicity. They feel great for prototyping but become limiting once you need to do anything beyond the narrow constraints they were designed around.
Look at workflow automation tools like n8n or Zapier. They're easy to pick up, but serious developers may need to build custom nodes or simply avoid them in favor of writing code because when you’re automating tasks, you need them to be done a certain way.
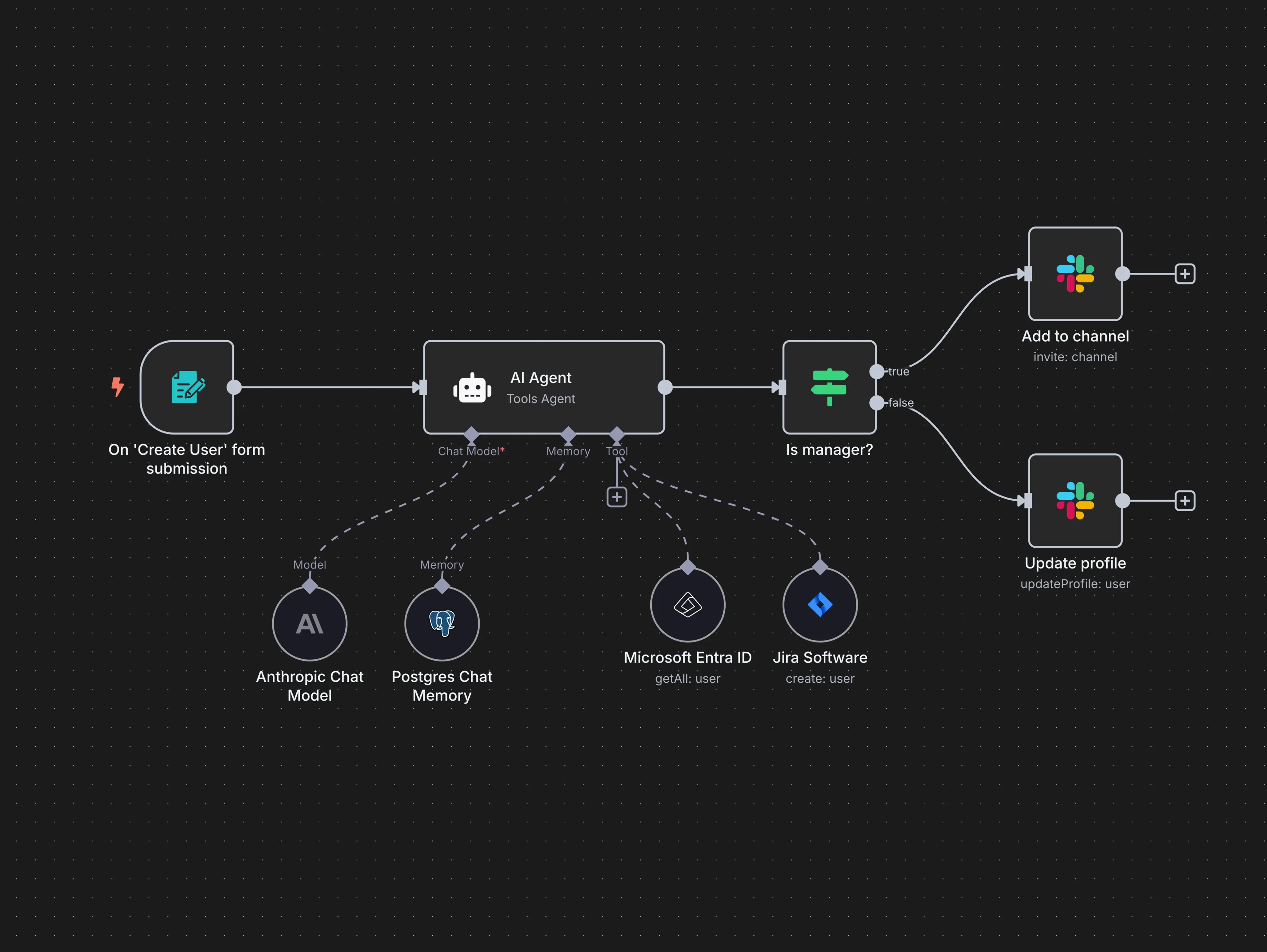
But real-time AI apps are not tasks to be automated. They are running continuously with different states and inputs/outputs. There’s an argument to be made that the challenges are amplified because of the complexity: how do you both design an app with multiple input streams and have that app do more than a single function (e.g. my personal trainer example)? But it turns out the answer is somewhere in the middle.
Why Graph Visualizations Work
Despite the drawbacks we just discussed, visualizing things as graphs actually makes a ton of sense for real-time, multimodal AI:
- Clarity: You immediately see what's happening, where data is going, and how nodes interact with each other.
- Easier Debugging: Problems become obvious when you can visually trace paths rather than sifting through logs or mentally tracking the different states.
- Better Collaboration: Non-engineers like designers or product managers can actually understand what's happening under the hood and even get their hands dirty, leading to better feedback and faster iteration.
What Game Dev Can Teach Us
There is an industry that has been real-time and multi-modal for a long time. They’ve had to deal with these problems for decades, and their tooling has evolved accordingly.
Game development deals with user inputs, collisions, sound, enemies, environments. Game engines like Unreal and Unity have already solved the same problems that multi-modal AI poses:
- Visual Blueprints: Graph-based editors that visually define states, events, and logic, while still providing hooks for custom scripting when you need it.
- Hybrid Approach: Keep high-level logic visual and intuitive, but let developers dive into code when they want more power or control.
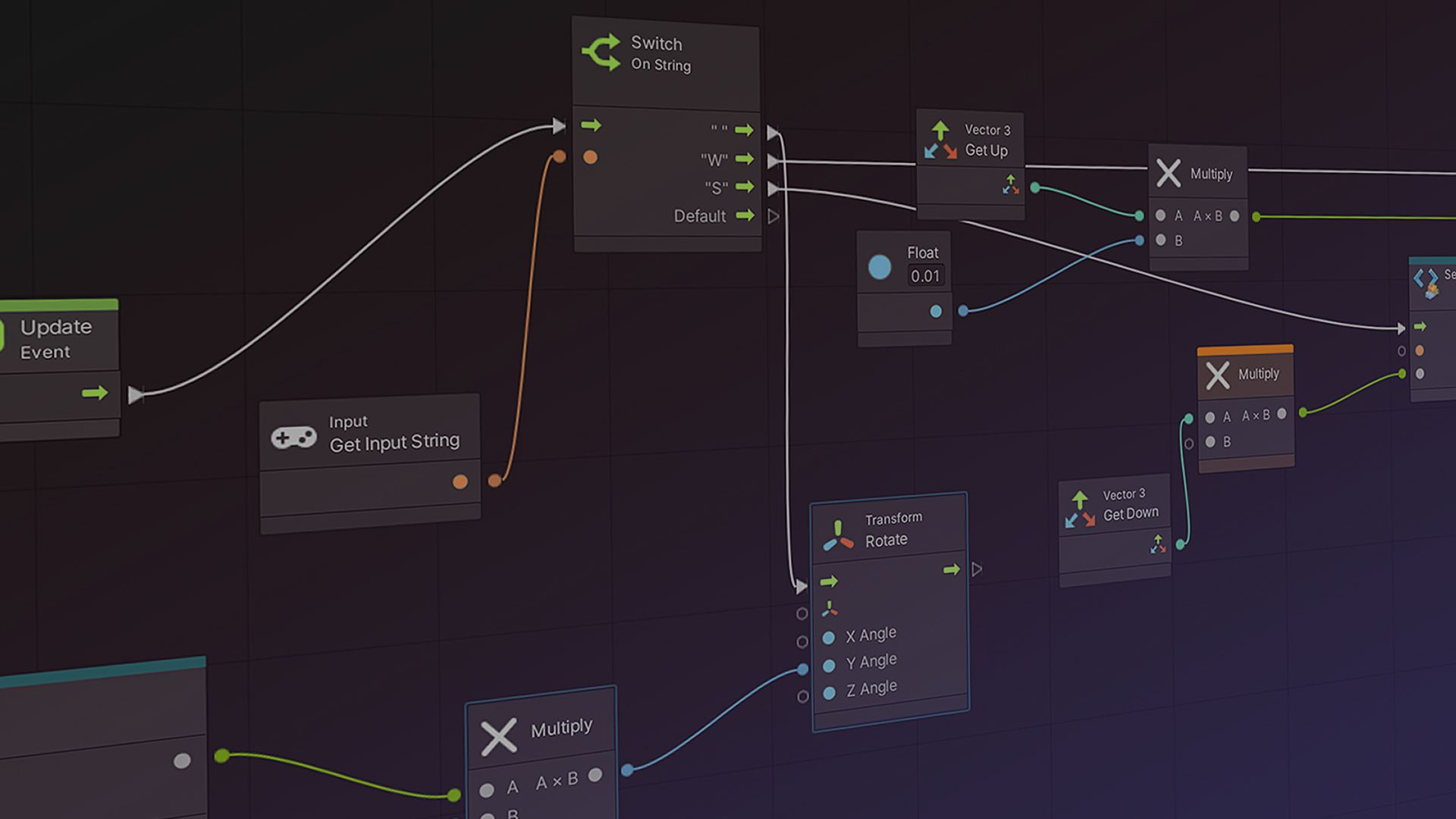
This is exactly how we see our frontend GUI shaping up for multi-modal AI. You’ll define interactions visually, connecting AI models, media inputs, and event triggers. But crucially, you’ll always be able to embed your own custom logic through code.
Striking the Balance
The best experience isn’t about being entirely visual or fully code-driven, it's probably something that blends the two in a way that makes sense:
- Quickly mock up multi-modal flows visually.
- Easily track down issue and iterate on them quickly.
- Dig into code whenever you want to customize further.
We’re building exactly that: a visual frontend that's actually useful for serious devs, without trading off the power or flexibility you need to build robust applications.
Real-time Client SDKs: Connecting Frontend and Backend
When it is time to deploy to production, the SDK layer lets you turn your creation into a product.
Gabber has SDKs for embedded ESP-32, robotics, and C-based applications, NextJS for the current wave of apps utilizing that framework, and Python for compatibility with Raspberry Pi and standard backend applications.
We also plan to release Unity and React Native + iOS for gaming and mobile use cases respectively.
Here’s what our SDK handles:
- Publishing media streams to the graph — camera, mic, screen, whatever.
- Listening for graph events — like model responses, output triggers, or state changes.
- Sending client-side events — like button clicks, gestures, or text input.
Whether you’re building for the web, iOS, Android, or something more exotic like robotics, the SDK makes deploying your Gabber graph to production simple.

The Benefits Of Gabber’s Hybrid Hosting + Graph Model
This approach isn’t just flexible — it’s also practical. It solves a bunch of the tough problems we’ve hit building real-time AI apps:
- Lower Latency: Everything is colocated, so inference is fast.
- Higher Quality: Fewer encoding hops means video and audio stay clean.
- More Control: Developers can plug in custom logic where it matters.
- Lower Cost: Piecing together 4-5 inference providers means 4-5 margins.

Conclusion
We’re building this system because we think real-time, multi-modal AI is the future, and current developer tools haven’t caught up.
Our approach blends hosted infrastructure represented as structured inference graphs, developer-friendly SDKs, and visual tools that allow teams to iterate quickly, all without compromising flexibility. It’s built for teams that want to move fast without giving up power or control to build applications that can’t exist without this system.
If that sounds like you, try it out. We’ll be launching a hosted cloud solution soon, but in the meantime we’re opening Gabber up via a Sustainable Use License so anyone can build locally, and we’ll be properly open-sourcing as we progress.
Join the community Discord: Gabber Discord
Check out the repo: Github ⭐️
