Building A Real-time AI Companion That Can See, Hear, And Talk To Users, Not Respond, Enforce Paywalls, And Interact
One of the questions I get most often is: "Can I build an AI companion that doesn't just take turns talking to me?"
The root of this question is two-fold:
- AI should be able to do more than speak. It should see, hear, speak, do things.
- AI should be able to deviate from the turn-taking script we're all used to with it's own sort of directives.
Turns out that stuff matters a lot. It's the difference between a toy demo and a product people actually pay for. And to get there, you need a system that can:
- See and hear (ingest audio and video in real time)
- Talk (speak and listen with low latency)
- Run Dynamic Scripts (change states, have opinions and desire, not respond sometimes)
- Interact (trigger tools, APIs, and external actions)
An example I heaar a lot is it'd be nice if the AI could do more than talk, and could also upsell things. Maybe the companion is $10/month to talk to. The AI should nudge the user to pay based on the relationship it has with the user. In the below video, I built just that.
It checks if the user is showing its "phone" and it nudges them to upsell in an unfortunately convicing way.
That's the future of AI companions we foresee. And it's finally possible to build.
Why This Problem Is Hard
It's easy to build a chatbot. It's hard to build a real-time, multimodal agent.
Why?
- Vision + audio ingestion: Taking in multiple media streams at once without dropping frames or losing context is non-trivial.
- Low latency output: People expect human-like responsiveness. Even a half-second delay can feel robotic.
- State and memory: An AI that is always on "one-track" is not a companion.
- Business logic: These companions are usually a product, so cleanly integrating upselling and paywalls without compromosing the experience is important.
This isn't solved by clever prompting. You need infrastructure and orchestration.
Building A Companion That Can See
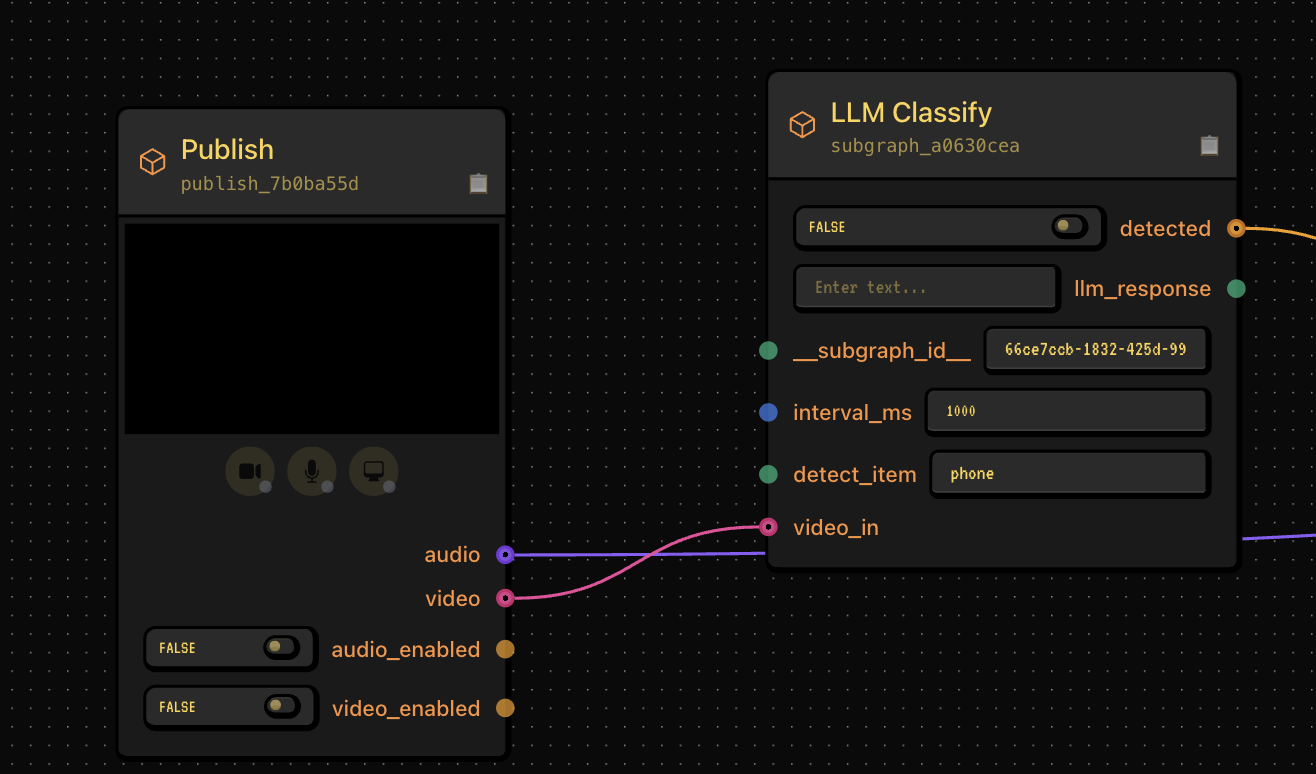
The first unlock was vision models that can run in real time.
Instead of a static "upload an image and I'll describe it" workflow, we stream frames continuously from the user's camera into the system using special networking and media pipelines.
Using lightweight Omni models and VLMs (Qwen 2.5 Omni / VL, Gemini 2.5, etc.), we can create applications that actually know what's going on, can hear things beyond speech, and can for all intents and purposes, see.
The companion can now:
- Detect if you're holding an object up to the camera instantly
- Watch your body language (are you exercising, waving, laughing, something else?)
- Programmatically react to changes in your environment (should it say something when you show it a special object? Should it change state when you're watching a movie vs just chatting?)
Think STT for video --- continuous, low-latency ingestion with context fed into the AI's prompt.
Building A Companion That Can Talk
Voice is non-negotiable.
Real companions don't wait 3 seconds to respond. They interrupt, they don't respond at the right time, they jump into the flow of conversation.
For this, you need:
- Fast STT (Speech-to-Text)
- Fast TTS (Text-to-Speech)
- Orchestration layer to handle interruptions, overlaps, waiting, and turn-taking
This is why Gabber incorporates APIs like Cartesia (Fast), ElevenLabs (Premium) and Gabber-hosted Orpheus (Expressive and Affordable). Pair them with a state machine to handle when the AI should speak versus when it should just listen, and you're in business.
Insert clip of AI state machine determining speaking back state
Run Dynamic Scripts
Now the fun part: how do you make it feel real?
If LLMs are turn-taking by nature, how do you go beyond that to build an AI that might have 2-3 of its own goals (get you to pay it, ask you to show it something, etc.)?
What about if you want your AI to act one way when you're just chatting, and another when you put on a movie to watch with it?
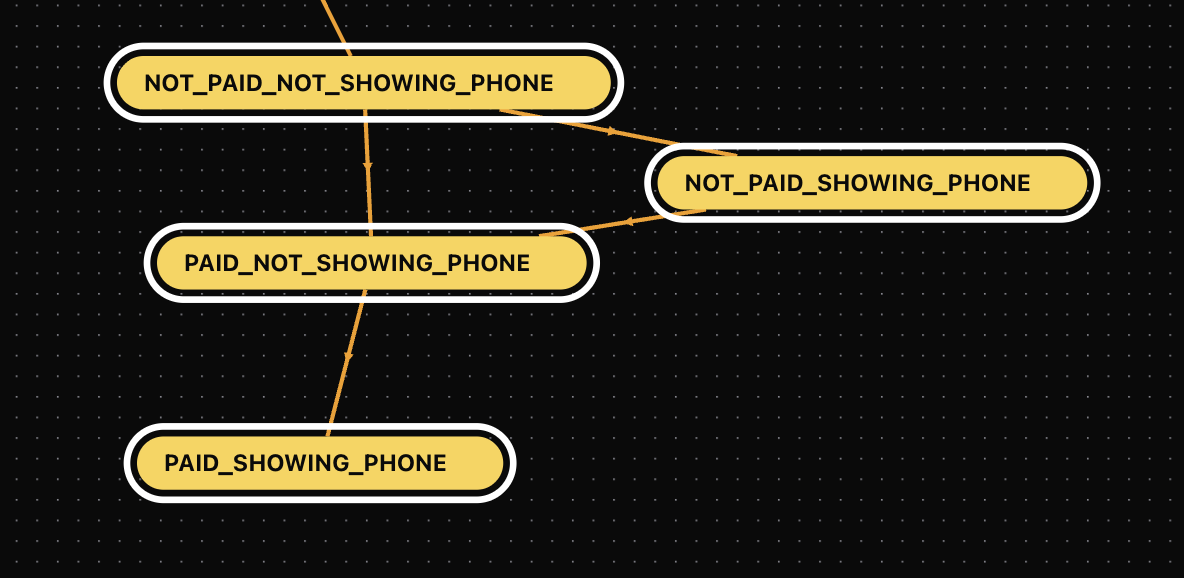
This is where State Machines become very interesting.
With a state machine you can all the sudeen make your AI do pretty much anything:
- Dynamically Change Prompts: It's common to try to jam everything into a prompt, but that falls apart quickly. Real-time companions should use smaller models for speed anyway, so using state machines, you can update the prompt based on what's going on in the conversation.
- Chain Together Models: Models are good at specific things, so use them together. Ask one model to listen for keywords, another to generate responses, a third to ingest the video feed. You can build custom logic based on each of these model outputs to make your application do anything.
- Soft nudges: As mentioned above, maybe the AI wants the user to do something. Given its context on the user, this should be a natural thing to inject into the conversation, and when the user does the thing, the AI should respond accordingly (see demo for simulating payment).
By combining these, you now have an AI that is less robotic in the traditional sense. It can multi-task, change, have it's own goals it acts on.
Making It Interactive
Finally, the killer feature: interactivity.
It's not enough for the AI to just see and talk. It has to do things.
That's where tool calling comes in.
Examples:
- Your fitness companion counts reps and logs them to a workout tracker.
- Your shopping companion sees a product you're holding and opens a purchase link.
- Your therapist companion sets reminders or sends you an encouraging message later.
- Your personal assistant plays Danger Zone by Kenny Loggins whenever you're feeling dangerous.
The state machine orchestrates this:
- A tool calling model detects an event "I'm feeling dangerous" and calls Spotify's API
- The voice model engages the user about it
- The conversational model keeps the conversation going
- The result flows back into the conversation
This is a simple demo, but you can see that even applying simple application logic allows you to build companions that are signficiantly more interactive.
Why This Matters
We've had chatbots. We've had talking assistants. But the next step is companions that see, hear, speak, have logic, and act.
And thanks to new real-time AI infra, this is very possible and something you can prototype in an afternoon.
If you want to build your own:
- Clone the repo
- Join the Discord
- Or wait for the cloud launch in the next couple of months
This is the frontier. Real-time, multimodal AI companions.
Links
- GitHub: gabber-dev/gabber
- Twitter: @jackndwyer
- Discord: Join here